How Enterprise Data Warehouse Impacts Businesses: Concept and Benefits Explained
Updated 23 Jun 2023
17 Min
2716 Views
Here’s a thing: as a business leader, you simply don’t have the luxury of delaying decisions. By implementing enterprise data warehouse (EDW), you receive the power to speed up the reporting process by 90%, enabling fast decision-taking. Why not integrate it?
In this post, I am going to figure out what an enterprise data warehouse is, consider its components, gains for various industries, and how to implement one for your company. So, let's get started!
What Is an Enterprise Data Warehouse?
An enterprise data warehouse (EDW) is a centralized repository that arranges and stores all the business data for analytics requests and reporting. The information can be extracted from different data sources like Enterprise Resource Planning (ERP) systems, Customer Relationship Management (CRM) systems, or physical recordings. As a result, enterprises can process large data sets from a single place using a data warehouse without managing multiple databases.
Think of it as a pie recipe. When you have only a recipe, you should go to the store (your data source) to get all the ingredients (your information). However, your ingredients may be unique, so you have to visit several stores situated in different parts of the city (your sales and marketing department). It takes much more time and money to bake such a pie. If you had a cupboard staffed with prepared and organized ingredients, you’d waste less time on cooking. This cupboard is your enterprise data warehouse.
Enterprise data warehouse vs. usual data warehouse
Any data warehouse is an extensive collection of organized and clean business information designed for reporting and analysis to support decision-making in an organization. If so, why do we separate enterprise data warehouses from usual ones?
The core difference lies in architectural diversity and functionality.
- Usual data warehouses (DWs) are small databases that collect and keep data for particular business units (e.g., sales data, customer data, etc.) and address department-specific needs.
- EDWs are complex structures divided into small databases and store information for all business units and respond to enterprise-level questions. Thus, it’s better to focus on enterprise warehouses to simplify query processing and cover the whole range of functionality.
Having business in healthcare? Explore what is data warehousing in healthcare: benefits, cost, and more
Best enterprise data warehousing solutions
Let’s consider the most demanded EDW solutions that completely meet the core criteria for data warehousing: instant expandability of storage resources, advanced performance, availability, high security, etc.
Amazon Redshift
Amazon Redshift is the most popular enterprise data warehouse provider. It’s a cost-effective, high-performance solution with a rich set of offered features. Its most exciting functionality is massively parallel data processing, columnar data storage, unlimited scalability, and query optimizer.
It allows clients to query large amounts of structured and semi-structured information and employ AWS infrastructure to improve customer experience. Redshift integrates with multiple services, business analytics tools, and platforms (e.g., Amazon QuickSight, Periscope Data, Tableau, etc.). Among Amazon Redshift’s well-known clients are McDonald’s, Yelp, Amazon.com, and Pfizer.
Price: On-demand pricing option set up for $0.25/hour. Reserved pricing provides users with discount capability (up to 75%) if they pay all up-front.
Google BigQuery
Google BigQuery stands for web service supported by Dremel technology and made to instantly process requests on massive structured datasets. The most prominent features are serverless architecture, multi-cloud capabilities, built-in machine learning (ML) and artificial intelligence (AI) integrations, and a spreadsheet interface.
Price: The service offers clients a 90-day free trial, after which they’re billed for the query, so users can only pay for features used.
Snowflake
Snowflake stands for the enterprise-level data warehouse built as a service in the Amazon Cloud. It’s capable of running any workload, allowing secure access to all business information, and delivers high-performance analytics for diverse enterprise needs.
The service enables independent storage and computation scalability, so clients can use and pay for those features separately. Its significant features are data and objects cloning, virtual compute warehouse, recover system object, change data capture.
Price: Snowflake provides customers with a 30-day free trial, and then the price will be based on the plan you choose.
What Does EDW Serve For?
Entrepreneurs from various fields can benefit from data analysis these days. Businesses that rely on information in the decision-making process can use EDW to assess the information gathered years ago and come up with the smartest business moves.
Furthermore, EDW software provides insights into the workflow of every company’s department. With comprehensive statistics about your employees’ workflow, you can optimize their work, reallocate workforces to other assignments, and even automate some repetitive tasks.
On top of that, with the help of EDW your analysts can focus on their tasks. They don’t have to figure out complex SQL queries and understand data structure because engineers have already done it for them. Now, analysts work with a user-friendly interface that doesn’t leave chances for confusion.
Let’s summarize the core benefits of enterprise data warehouse solutions:
- Reduced time to understanding of business workflow due to combined enterprise data prepared for analysis.
- Enhanced employees’ productivity and the addressing the communication issues across the business units due to easy access to consolidated and quality information.
- Saved data analysts’ time through automated data processing (data gathering, forming, transformation, transmission, cleansing, etc.).
- Increased data accuracy, coordination, and security due to a centralized information management approach.
- A robust foundation for sophisticated analytics initiatives.
- Extension of data awareness across the corporation.
How industries use data warehouse
Healthcare
A healthcare data warehouse consolidates and stores medical information from different sources in a healthcare system: EHRs, EMRs, supply chain, claims, administrative database, health surveys, etc. It enables healthcare institutions to thoroughly and systematically monitor patients’ disease and conditions, care delivery processes and then produce data-driven decisions to enhance patient and clinical outcomes and reduce operational costs.
Retail
With data warehousing, analysts can process and analyze tons of data to predict the demand for certain goods, conduct market research, and find new distribution channels. It also helps track the item's performance, consumers buying patterns and create a flexible pricing policy. You can either raise or lower the price depending on real-time market conditions.
Finance
Enterprise data warehouses allow financial organizations to capture every interaction with a client, obtaining insights on what drives customers’ decisions. Banks can use EDW technology to categorize and store client data. This submits immediate access to the information when it needs to be analyzed. For example, analytics can assess clients' credit history and decide whether to approve or decline their loan requests with data mining algorithms.
Learn the role of data warehouse in business intelligence solutions in our guide
Data Warehouse Types
As we’re already clear with the concept of enterprise data warehouse it’s high time to dive into more technical details of EDW and get acquainted with different types of data warehouse.
Enterprise Data Warehouse
EDW is the first and most common type of data warehouse. Companies use an EDW database to keep heterogeneous data from various sources in one place. After the extraction, transformation, and loading (ETL process), the data can be used for trend analysis and reporting. The enterprise data warehouse is the only type of data warehouse that stores extensive information from a variety of subject areas.
Operational data store
Unlike enterprise data warehouse solutions, operational data stores gather and keep short-term data. The ODS information is updated in real-time (every minute, every hour), and the data retention period becomes much lower compared to EDW. This type of storage is suitable for analysis of everyday tasks and superficial personnel performance analysis.
Data mart
Data Mart is the same as an enterprise data warehouse except for one detail. While EDM saves all the data related to the company, Data Mart stores only a certain department's information. Thus, marketing and sales departments will have two different data marts. This type of storage can be used for highly accurate performance overviews of separate departments.
Data lake
Data lake is a great place to locate row, structured, and unstructured data quickly to clean and organize it later. It’s also called data on demand. When the needed information is queried, the data subgroup is chosen based on specific criteria and submitted to data analysts. The core purpose of the data lake is to explore, order, and analyze the information coming from multiple resources.
Data warehouse vs. data lake vs. data mart
There is often confusion between these terms. Sometimes, they’re even used interchangeably. But the differences come down to purpose, structure, data types, data origin, and data access rights. So let's go into all the details about the difference.
Data warehouse
Data warehouse is more purpose-specific than a data lake or data mart. It’s well suited for enterprises that have a massive amount of information from multiple data origins. It's an extensive repository of structured, optimized data, so that the end-users can obtain large-scale results. These warehouses are primarily used for Business Intelligence (BI), batch reporting, and data visualization. The size ranges between 100 GB and petabytes.
Data mart
Data mart is a subset of the data warehouse that’s highly curated for a particular business domain (e.g., finance data mart). It’s mainly used to spread information by domain and link to each other. However, this data can hardly be applied to enterprises because of their small size (less than 100 GB). Commonly, data marts are meant to split large data warehouses into more workable ones.
Data lake
Data lake is comprised of raw, free-flowing data that can be presented in any data type (images, texts, files, videos). It’s an emerging technology that holds data in its native format until it’s required. In contrast, in data warehouses, there is a predefined reason for storing data. The data lake is mostly used in machine learning, predictive analytics, and data discovery, answering specific business requests.
| Parameters | Data Warehouse | Data Mart | Data Lake |
Type of data | Structured, curated | Highly curated | Raw, structured, unstructured, |
Size | More than 100 GB | Less than 100 GB | Any size of data |
Purpose | Data stored for business intelligence, batch reporting, data visualization | Data used by specific business units for analysis | Data used for predictive analytics, data discovery, machine learning |
Typical users | Data analysts | Data analysts | Data analysts, data engineers, data scientists |
Enterprise Data Warehouse Architecture
EDWs have a complex architecture because they need to transmit, cleanse, store, and analyze the data. Each of these functions requires a separate layer that deals with its task. Usually, the whole data pipeline is structured with three layers:
- Single-tier architecture
- Two-tier architecture
- Three-tier architecture
Let’s single out each architecture type and figure out their levels.
Single-Tier Architecture
It’s the least popular approach for enterprise data warehouse development. Single-tier architecture implies that the client, database, and server resides on the same machine. Because of the limited resource capacity, this strategy requires users to save as little information as possible. That’s why this architecture is suitable for minor projects or business logic testing.
Two-Tier Architecture
Two-tier, or also known as client-server architecture, is less popular among database engineers than three-tier architecture. The characteristic feature of this type is the direct communication between the user and the server. The two-tier system consists of client applications and server databases.
This EDW architecture is easier to create and maintain. Without the online analytical processing (OLAP) layer, the data transmission gets faster. Still, two-tier EDW software is hard to scale. It makes this architecture less cost-effective with the growth of users. On top of that, a lack of OLAP level makes employees spend more time on data analysis.
Three-Tier Architecture
This is the most widely used enterprise data warehouse architecture type. It includes three tiers responsible for different assignments.
Bottom Tier
This level is a database itself. Developers usually use relational databases for EDW solutions. Here, the ETL process happens, and the system prepares data for further analysis.
Middle Tier
Here we have an OLAP system. This system is a data discovery and analysis system that helps your business analysts to work with the data effectively. All predictions, reports, and charts are processed at this stage.
There are two types of OLAP systems:
- MOLAP. An analytical system that works with multidimensional databases. MOLAP solutions are usually easy to master because of short queries and top-notch optimization.
- ROLAP. The same system that works with relational databases. ROLAP systems have complex queries and require an experienced employee to work with the data warehouse. However, it has a strong advantage over MOLAP. A ROLAP-based EDW software is more scalable because it handles larger volumes of data.
The middle tier is a kind of mediator between the EDW database and the end-user. Still, it’s hard for non-tech users to deal with the database without the interface. That’s why we need a section responsible for user interaction.
Top Tier
The top tier is a layer that simplifies the lives of ordinary users. Here, developers take care of the interface for end-users. Mind that the interface should be intuitive and clear for your employees.
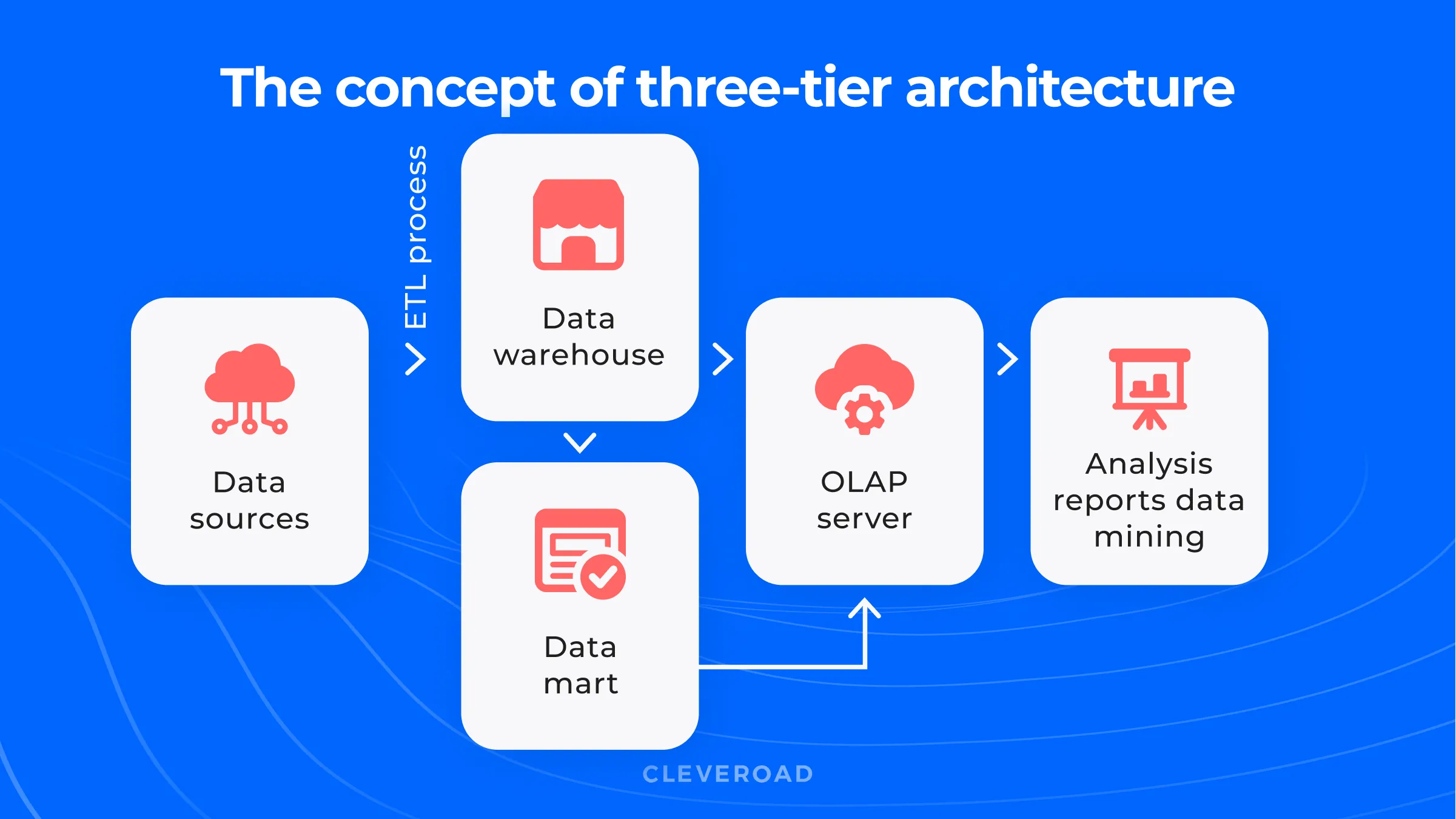
Three-tier architecture explained
Enterprise Data Warehouse Types
There are two most popular ways in which a data warehouse can be deployed. Let’s check it out.
On-Premises
This environment type implies that enterprises are in charge of buying, setting up, and supporting software and hardware needed to handle the data warehouse.
Pros:
- Control. The companies get to maintain complete control over the entire tech stack.
- Speed. You can leverage your local network speeds avoiding some bandwidth challenges typically associated with the cloud.
- Security. Only a person who is connected to the company's network can access all the information stored.
Cons:
- Increased costs. It requires significant investments and ongoing support and maintenance. Moreover, as data volume grows, there is a need for purchasing extra hardware to accommodate this data.
Cloud
In the case of a cloud-based enterprise data warehouse, the information is delivered as a managed SaaS offering via multiple public cloud providers. Therefore, there is no need to purchase software or hardware, only pay for cloud solutions.
Pros:
- Flexibility. Instead of just managing systems, you can free up your resources to focus on high-value analytics tasks.
- Reduced costs. You don’t need to go out and procure the hardware and software.
Cons:
- Security. Since all the data is stored in the cloud and can be accessed over the Internet, there are confidential data breach risks.
Thinking of deploying EDW in cloud? Don't miss out our latest guide on Cloud Business Intelligence and its advantages for enterprises
Components to Create EDW
As you already know, a full-fledged enterprise data warehouse is a complex project that includes many components and steps you need to take. Database engineering, ETL process, data analysis algorithms, and other parts of your system take a lot of development time. On top of that, you have to find a skillful software development company that can handle this task.
Now, let’s figure out the components of the data warehouse that should be thought over during the development.
Database
EDW database is the core of the whole structure. First things first, you have to decide on the database type. Usually, developers use relational databases for enterprise data warehouses. Relational or SQL databases grant high scalability potential and minimize the chance of anomalies. However, this approach works with precise and structured data.
If that’s not your case, you can go with the NoSQL database. NoSQL gives you more flexibility. If you can’t set the role for your data in the database, just save it with NoSQL. While relational databases require each piece of data to have a type, NoSQL lets you save separate files to folders. For example, you can save a whole blog page to the database as a flat file. Afterward, you can extract the data you need and manipulate it.
Still, if you’re working with sensitive data like users’ payment details, relational databases are required. Unorganized storing of sensitive data is forbidden by data security protocols.
ETL Process
To put all the data in order, developers use data sourcing, transformation, and migration tools. Let’s single out each step of the extraction, transformation, and loading process.
Extraction
Here, your enterprise data warehouse extracts the data from various sources. The data can be in different formats like SQL, NoSQL, XML files, flat files, and more. The main requirement is to store extracted data into the waiting area. You can’t place the data directly into the EDW database because it should be transformed into a unified format first. Mixing data types may ruin the whole structure of your repository and corrupt already existing information.
Transformation
In the second stage of the ETL process, the system transforms your data into a unified format. Here are some examples of transformations:
- Filtering. Filtering the data by attributes. If the attribute doesn’t match with the required ones, it won’t be loaded into the data warehouse.
- Merging. Unifying separate attributes into one (for example, make one “First/Last Name” out of two “First Name” and “Last Name” attributes).
- Sorting. Sorting data based on some criteria (sorting employees’ salaries from minimal to maximal in a certain department).
- Cleaning. Filling up the NOT-NULL variables with some data, converting acronyms to full names.
Loading
After dealing with all the steps, the system is ready to load data into the warehouse. Depending on the data warehouse type, you can set the update frequency of your storage. For example, operational data stores can refresh the data every few minutes, while enterprise data warehouses can load new data daily or even weekly.
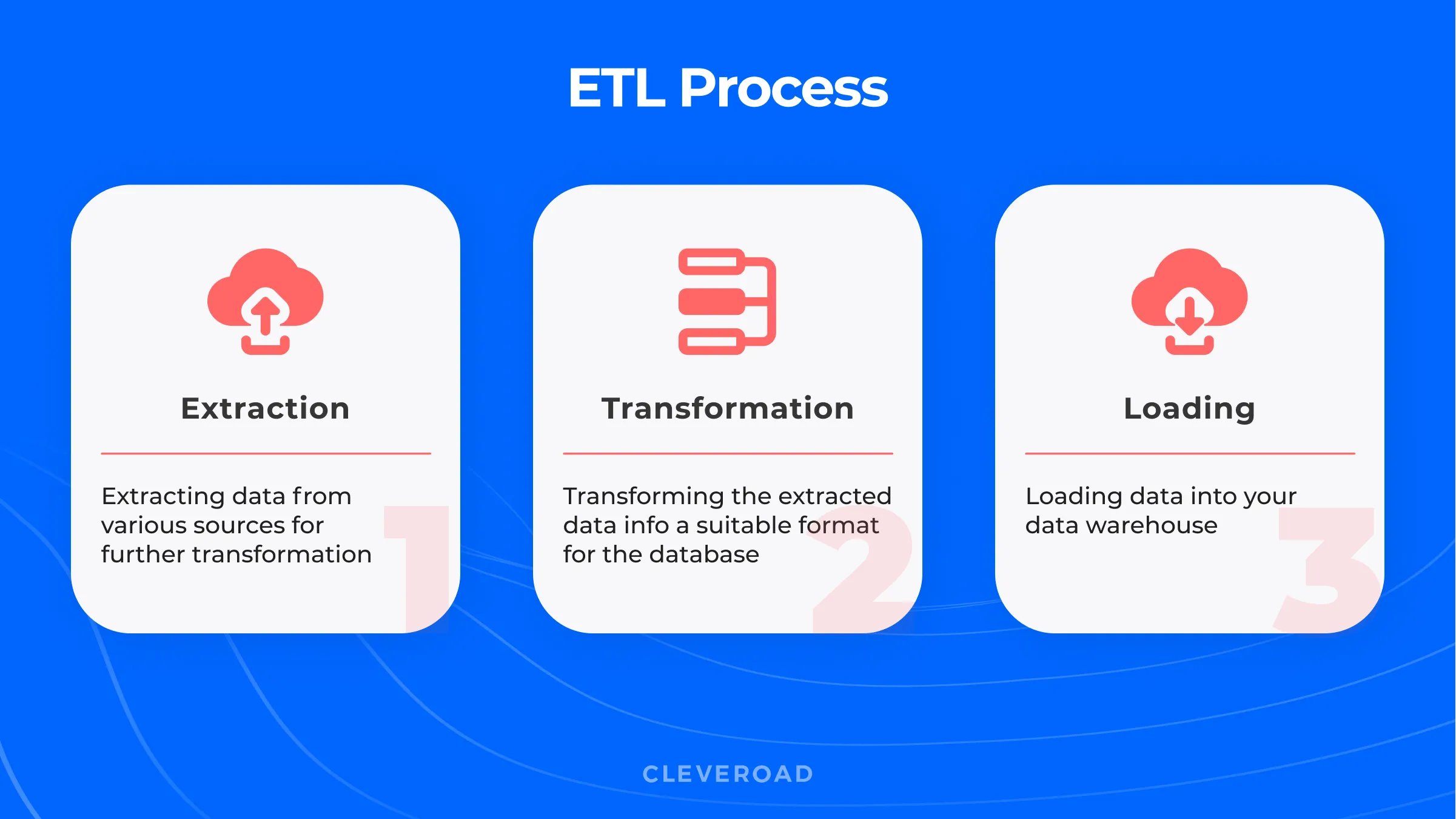
Steps of ETL process
Metadata
Metadata is the information about the data inside your EDW database. It may be confusing at first, but the example will clear things out. Let’s take a look at the following data:
Ph2458 Pt8234 129.00 00:34:23
At first, this seems like a useless combination of letters and digits. But the metadata will explain everything:
- Ph2458 - the physician’s ID
- Pt8234 - the patient’s ID
- 129.00 - the cost of the visit
- 00:34:23 - the length of the visit
That’s how healthcare establishments keep the data about each visit to a certain doctor. Thus, metadata keeps information that helps to understand the data inside the warehouse. Metadata may also contain details about the origin of data, the last attempt of modification, where it is stored, and more.
Query Tools
The primary aim of enterprise data warehouses is to provide comprehensive reports and clear information for analysts. But it’s impossible without correctly configured query tools.
Data mining algorithms are a primary concern for EDW software developers. Data mining lets analysts find new correlations, trends, and patterns in large volumes of data. With these algorithms, analysts can detect new opportunities and improve the decision-making process.
Steps to Build an EDW
It’s obvious that such a labor-intensive project as an enterprise data warehouse requires a whole team of developers that’ll take care of this job for you. But as a project owner, you still have your responsibilities that are crucial for the whole development process.
Clearly define the requirements
Before searching for a tech partner, you should clearly understand the purpose of data warehouse in your enterprise. Analyze the amount of data you need to store and what profits will automation of analytics processes bring to your business. After the assessment, it may appear that a simple database and business intelligence tools like SAP or Microsoft Power BI will be enough for you.
If you’re still sure that an enterprise data warehouse is your choice, you have to decide on the subject field, warehouse type, and architecture. These issues are hard to manage for a non-tech person, so you should find a software development company that has an experienced database engineer. Together, you can figure out what solution will be the best match for your business. Don’t forget about the feature list for your data warehouse. Without clear requirements, your development team can’t get to work.
Find a reliable tech partner
The success of the whole project depends on the experience of the software development company. When searching for a tech partner, pay attention to the number of successful projects, their complexity, and what technologies were used during the development processes.
Here, you can learn how to hire computer programmers with the right skills for your business tech initiatives
Besides, keep an eye on the company’s set of services. If the team focuses on IoT devices or mobile development, this company may not have experience in managing complex EDW databases. That’s why you should search for a company that has an in-depth knowledge in the field you need.
Finally, the development cost also plays a vital role in the choice of your partner. Developers from different regions have different rates. Here are hourly rates in the most well-known outsourcing tech hubs.
To find a perfect tech partner that will fulfill all your expectations, you should conduct research. Services like Clutch and GoodFirms display client reviews about software development companies. We strongly recommend checking clients’ feedback before contacting the company.
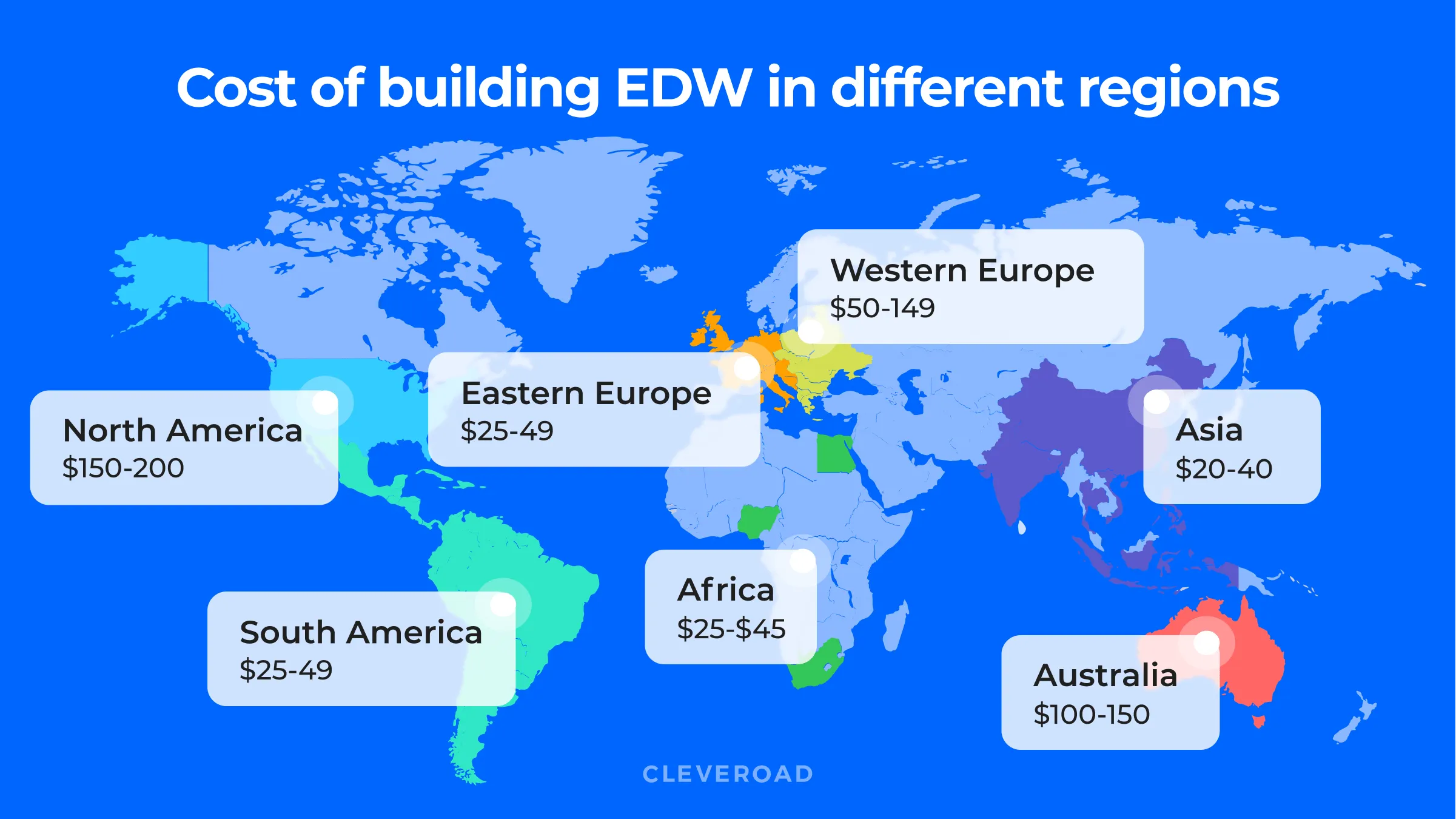
Developers' rates in different regions
How Can Cleveroad Help You?
Cleveroad is a professional software development company located in Estonia, Central Europe. With over 12+ years in IT consulting and software engineering, we have built up expertise in multiple domains, including e-commerce, retail, logistics, education, healthcare, and other business industries.
We have a huge pool of experienced specialists that helped hundreds of enterprises build and integrate data management solutions. Our database engineers are proficient with relational and NoSQL databases. They know how to create database structures and complex queries to create EDWs with top-notch performance.
By collaborating with us, you'll receive:
- Detailed product roadmap of EDW implementation and actionable recommendations from our data analysts, solution architects, and software engineers
- Proficiency in integrating your EDW system with third-party solutions, such as BI and ML/AI analytics tools
- The pool of 250+ certified software engineers that are proficient in technologies to build and support EDW solutions: Microsoft SQL Server, MySQL, PostgreSQL, NoSQL databases, ETL tools like IBM DataStage, Apache NiFi, data modeling tools, etc.
- All-out Project Management Office for overseeing your projects to perform them on time, within the budget, and in line with your business requirements
- Expertise in providing cloud consulting services assured by receiving Amazon Web Services (AWS) Select Tier Partner status within the AWS Partner Network (APN)
- Experience with cloud computing services such as Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, etc., for deploying and handling cloud EDWs
Get your EDW system estimation now!
Contact us to know how much your enterprise data warehouse implementation will cost you
To build an enterprise data warehouse you have to clearly understand the requirements for the project. Depending on your demands, you should choose the type of data warehouse, architecture, and other aspects. After research, you should find an experienced software development company that will build the project for you.
EDW is the first and most common type of data warehouse. Companies use an EDW database to keep heterogeneous data from various sources in one place. After the extraction, transformation, and loading (ETL process), the data can be used for trend analysis and reporting. The enterprise data warehouse is the only type of data warehouse that stores extensive information from a variety of subject areas.
Businesses that rely on information in the decision-making process can use EDW to assess the information gathered years ago and come up with the smartest business moves. With comprehensive statistics about your employees’ workflow, you can optimize their work, reallocate workforces to other assignments, and even automate some repetitive tasks.
- Enterprise data warehouses help to predict events and analyze market trends
- EDWs assist in analyzing the productivity of employees and companies' departments.

Evgeniy Altynpara is a CTO and member of the Forbes Councils’ community of tech professionals. He is an expert in software development and technological entrepreneurship and has 10+years of experience in digital transformation consulting in Healthcare, FinTech, Supply Chain and Logistics
Give us your impressions about this article
Give us your impressions about this article
Comments
4 commentsInformative and on-point, as always!
This article explained a lot of obscure moments. We're going to develop our own enterprise data warehouse, but don't know where to start with. Thanks for giving us a lead.
Hey! It's also a good idea to go for cloud architecture. Unlike a physical one, you don't have to buy equipment and rent additional space. Still, thanks for your efforts on this article.
Awesome content! Keep up the good work